PyOpenCLハンズオン in kyoto.py(2011年9月24日)¶
チューター: おのうえ(@_likr)
テストサーバー(当日のみ公開)
ssh ユーザ名@aws-1.likr-lab.com
Amazon Web Service Cluster GPU Instance
- Xeon X5570 × 2
- NVIDIA Tesla c2050 × 2
- 22GB RAM
- Python2.7 + PyOpenCL
- NVIDIA OpenCL
イントロダクション¶
いきなりデモ¶
PyOpenCLによるマンデルブロ集合の描画
import time
import pyopencl
from pyopencl import mem_flags
import numpy
from PIL import Image
src = '''
__kernel void mandelbrot(
__global uchar* out,
float pixel_size,
float x0,
float y0,
int max_iter,
float threshold
)
{
const int i = get_global_id(1);
const int j = get_global_id(0);
const float cr = x0 + pixel_size * i;
const float ci = y0 + pixel_size * j;
float zr = 0.0f;
float zi = 0.0f;
float zrzi, zr2, zi2;
int k;
for(k = 0; k < max_iter; k++) {
zrzi = zr * zi;
zr2 = zr * zr;
zi2 = zi * zi;
zr = zr2 - zi2 + cr;
zi = zrzi + zrzi + ci;
if(zi2 + zr2 >= threshold) {
break;
}
}
if(k > 255){
k = 255;
}
const int base = (j * get_global_size(1) + i) * 3;
out[base] = 255 - k;
out[base + 1] = 255 - k;
out[base + 2] = 255 - k;
}
'''
def main():
context = pyopencl.create_some_context()
queue = pyopencl.CommandQueue(context)
program = pyopencl.Program(context, src).build()
width = 300
height = 200
pixel_size = numpy.float32(0.01)
x0 = numpy.float32(-2.)
y0 = numpy.float32(-1.)
max_iter = numpy.int32(256)
threshold = numpy.float32(2.)
out = numpy.empty((height, width, 3), numpy.uint8)
out_buf = pyopencl.Buffer(context, mem_flags.WRITE_ONLY, out.nbytes)
global_size = (height, width)
start = time.time()
program.mandelbrot(queue, global_size, None, out_buf, pixel_size, x0, y0, max_iter, threshold)
event = pyopencl.enqueue_copy(queue, out, out_buf)
event.wait()
stop = time.time()
image = Image.fromarray(out)
image.save('mandelbrot.png')
print stop - start
if __name__ == '__main__':
main()

出力結果
OpenCLって何?¶
上述の通り、OpenCLは並列計算のフレームワークです。OpenCLが扱う並列計算とは、マルチコアCPUでのマルチプロセス、マルチスレッドプログラミングだけではなく、GPUやDSP(デジタルシグナルプロセッサ)などCPU以外のプロセッサでの計算も含みます。
OpenCLが注目を浴びてる大きな理由の一つはGPUコンピューティングができることでしょう。GPUコンピューティングをするためには、NVIDIAのGPUならCUDA、AMDのGPUならATI Streamと、別個のフレームワークを学ぶ必要がありました。しかしOpenCLなら一つのソースコードでNVIDIAのGPUにもAMDのGPUにも対応したコードが書け、更にCPUなどOpenCLがサポートした並列処理環境全てで実行できるようになります。
参考資料
GPUコンピューティングの魅力¶
インストール¶
Python2系を想定
OpenCLのインストール¶
各プラットフォームベンダーが配布しているOpenCL環境のどれかをインストールします。
Mac OS X 10.6 SnowLeopard, 10.7 Lion の人¶
XcodeをインストールすればApple OpenCLがインストールされます。
Intel OpenCL¶
以下のリンクからダウンロードしてインストールします。 Mac版はありません。
http://software.intel.com/en-us/articles/download-intel-opencl-sdk/
依存ライブラリのインストール¶
pip install numpy
pip install mako
PyOpenCLのインストール¶
pip install pyopencl
PyOpenCLの基礎¶
PyOpenCLプログラムに必要な4つの要素
- Context
- CommandQueue
- Buffer(メモリーオブジェクト)
- Kernel
Context¶
context = pyopencl.create_some_context()
複数のプラットフォーム、デバイスが存在する場合、どれを使用するか対話的に決定する。 対話的に決定せずに自動選択させる場合はcreate_some_contextの引数にinteractive=Falseと渡してやる。
CommandQueue¶
queue = pyopencl.CommandQueue(context)
Buffer¶
Bufferの作成
# ホストからデバイスへデータを渡す用
a = numpy.random.rand(50000).astype(numpy.float32) # ホストメモリ
a_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=a) # デバイスメモリ
# デバイスからホストへデータを受け取る用
b = numpy.empty(50000, numpy.float32) # ホストメモリ
b_buf = pyopencl.Buffer(context, mem_flags.WRITE_ONLY, b.nbytes) # デバイスメモリ
# ホストからデバイスへデータを渡し、デバイスからホストへデータを受け取る場合
c = numpy.random.rand(50000).astype(numpy.float32) # 干すとメモリ
c_buf = pyopencl.Buffer(context, mem_flags.READ_WRITE | mem_flags.COPY_HOST_PTR, hostbuf=c) # デバイスメモリ
メモリオブジェクト間の転送
d = numpy.random.rand(50000).astype(numpy.float32)
buf = pyopencl.Buffer(context, mem_flags.READ_WRITE, d.nbytes)
e = numpy.empty_like(d)
pyopencl.enqueue_copy(queue, buf, d) # ホストからデバイスへの転送
pyopencl.enqueue_copy(queue, e, buf) # デバイスからホストへの転送
enqueue_copyの第2引数が転送先、第3引数が転送元。
Bufferの作成時にhostbufを指定した場合はホストからデバイスへの転送は自動で行われる。
Kernel¶
カーネル関数と呼ばれるデバイスで実行される関数のコードを、文字列としてProgramオブジェクトのコンストラクタに渡します。
OpenCLのデバイスには1つまたは複数の演算ユニットが存在して、それぞれの演算ユニットは1つまたは複数のプロセッシングエレメントを持っています。
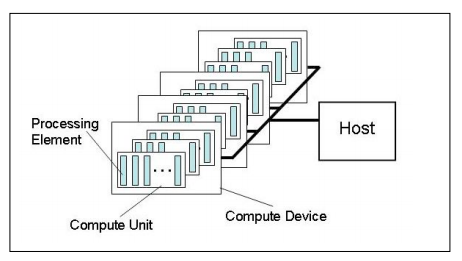
OpenCLプラットフォームのモデル(OpenCL Specification 1.1より)
OpenCLではひとまとめの処理を複数のワークアイテムという処理単位に分割して、それぞれのワークアイテムをプロセッシングエレメントが処理していきます。ワークグループとはワークアイテムのまとまりで、あるワークグループに属するワークアイテムは1つの演算ユニット内で処理されます。演算ユニット間ではメモリアクセスや同期処理に制限がありますが、演算ユニット内ではそれらの制限が緩るむので、ワークグループのサイズを適切に決定するのも時には必要です。ワークアイテムの総数をグローバルサイズ、各ワークグループ内のワークアイテムの数をローカルサイズと呼びます。ワークアイテムにはIDが割り当てられていて、全ワークアイテムを一意に識別するIDをグローバルID、ワークグループ内で識別するIDをローカルIDと呼び、カーネル関数内でそれぞれget_global_id関数、get_local_id関数を呼び出すことで得られます。
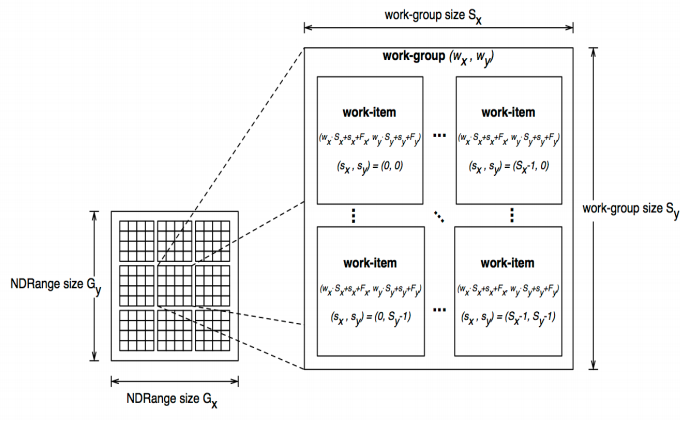
OpenCLのワークグループ(OpenCL Specification 1.1より)
プログラムオブジェクトの作成
program = pyopencl.Program(context, '''
__kernel void sum(
__global const float* a,
__global const float* b,
__global float* dest
)
{
const int gid = get_global_id(0);
dest[gid] = a[gid] + b[gid];
}
''').build()
カーネル関数の呼び出し
program.sum(queue, (5000,), None, a_buf, b_buf, dest_buf)
第1引数がコマンドキューオブジェクト、第2引数がグローバルサイズを指定する整数のタプル、第3引数がローカルサイズを指定する整数のタプル、それ以降がカーネル関数の引数になります。ローカルサイズを特に指定しない場合はNoneを渡します。
課題1¶
OpenCLを使って、ベクトルaとbからa-bを計算してみましょう。 TODOの部分にプログラムを書いていきましょう。 0.0が出力されるようになれば正解です。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import mem_flags
import numpy
from numpy import linalg
size = 50000
a = numpy.random.rand(size).astype(numpy.float32)
b = numpy.random.rand(size).astype(numpy.float32)
dest = numpy.empty_like(a)
# TODO
print linalg.norm(dest - (a - b)) # 結果の検証
課題2¶
ワークアイテムの概念になれるため、配列を反転させるプログラムを書いてみましょう。 カーネル関数内でget_global_size(0)とするとグローバルサイズが取得できます。こちらも0.0が出力されるようになれば正解です。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import mem_flags
import numpy
from numpy import linalg
size = 50000
a = numpy.random.rand(size).astype(numpy.float32)
dest = numpy.empty_like(a)
# TODO
print linalg.norm(dest - a[::-1]) # 結果の検証
パフォーマンスを考える¶
ここでのパフォーマンスチューニングは、NVIDIA GPUを対象としています。AWSのテストサーバを利用してください。ネットワークの遅延が大きいと思うので、手元の環境でテスト実行してからscpでサーバにアップして実行とかするのがいいと思います。
行列積のプログラム¶
行列積の計算では以下のPythonプログラムのような処理を行います。これをPyOpenCLで高速化していきます。
# -*- coding: utf-8 -*-
import numpy
from numpy import linalg
size = 64
a = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
b = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
dest = numpy.empty_like(a)
for i in range(size):
for j in range(size):
for k in range(size):
dest[i, j] += a[i, k] * b[k, j]
PyOpenCL版行列積¶
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import mem_flags
import numpy
import time
size = 1024
a = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
b = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
dest = numpy.empty_like(a)
context = pyopencl.create_some_context(interactive=False)
queue = pyopencl.CommandQueue(context)
a_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=a)
b_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=b)
dest_buf = pyopencl.Buffer(context, mem_flags.WRITE_ONLY, dest.nbytes)
program = pyopencl.Program(context, '''
__kernel void matrix_mul(
__global const int* a,
__global const int* b,
__global int* dest,
const int n
)
{
const int i = get_global_id(0);
const int j = get_global_id(1);
const int dest_index = j * n + i;
dest[dest_index] = 0;
for(int k = 0; k < n; k++){
dest[dest_index] += a[j * n + k] * b[k * n + i];
}
}
''').build()
n = numpy.int32(size) # カーネル関数にスカラー値を渡すにはnumpyの型を使う
start = time.time()
e = program.matrix_mul(queue, a.shape, None, a_buf, b_buf, dest_buf, n)
e.wait()
stop = time.time()
pyopencl.enqueue_copy(queue, dest, dest_buf)
print numpy.all(numpy.dot(a, b) == dest)
print stop - start
カーネル関数の実行時間を測る¶
カーネル関数は非同期で実行されるので、カーネル関数呼び出し時の返り値のEventオブジェクトを使って処理の終了を待ちます。時間の測定は簡易的にtimeを使うことにします。
start = time.time()
e = program.kernel(queue, a.shape, None, args)
e.wait()
stop = time.time()
print stop - start
デバイスの情報を知る¶
OpenCLは様々な並列計算環境を標準化したフレームワークです。しかし実際にはCPUでの並列計算とGPUでの並列計算では処理能力や特徴が異なっていたりして、特定のデバイスで高いパフォーマンスを出すためにはそのデバイスに適したコーディングを行わなければいけません。
以下のようにしてPyOpenCLからデバイスの情報を取得することができます。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import device_type
from pyopencl import device_local_mem_type
platform = pyopencl.get_platforms()[0]
device = platform.get_devices()[0]
print '''
Name = {}
Type = {}
Max Compute Units = {}
Max Work Group Size = {}
Max Work Item Dimensions = {}
Max Work Item Size = {}
Local Mem Size = {}
Local Mem Type = {}
'''.format(
device.name,
device_type.to_string(device.type),
device.max_compute_units,
device.max_work_group_size,
device.max_work_item_dimensions,
device.max_work_item_sizes,
device.local_mem_size,
device_local_mem_type.to_string(device.local_mem_type)
)
実行例:
Name = Intel(R) Core(TM) i7-2677M CPU @ 1.80GHz
Type = CPU
Max Compute Units = 4
Max Work Group Size = 1024
Max Work Item Dimensions = 3
Max Work Item Size = [1024, 1, 1]
Local Mem Size = 32768
Local Mem Type = GLOBAL
他にも取得できる情報はたくさんあるのでPyOpenCLのドキュメントを参照してください。
OpenCLのメモリ階層¶
OpenCLデバイスのメモリにはいくつかの種類があり階層構造をしています。ここまででホストとデバイス間のデータのやり取りに使用していたのはグローバルメモリでデバイスからアクセスできます。これまでは明示的に宣言はしていませんでしたが、カーネル関数内で定義した変数などはプライベートメモリに該当し、各ワークアイテムの中でしかアクセスすることができませんが、GPUではグローバルメモリと比較して高速にアクセスができます。ローカルメモリはその中間に位置し、各ワークグループごとにローカルメモリを持っています。デバイスがGPUの場合はローカルメモリは高速化に重要な役割を果たしたりします。
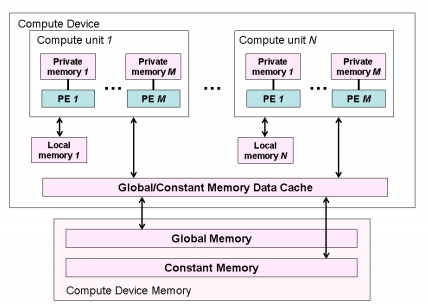
OpenCLのメモリ階層(OpenCL Specification 1.1より)
グローバルメモリへのアクセスはプロセッサでの演算と比較すると極めて低速になります。CPUではL1キャッシュ、L2キャッシュなどの仕組みを持っていてグローバルメモリへのアクセスを自動的に減らします。一方で、GPUでは多くの場合、明示的にプライベートメモリやローカルメモリを使用して、メモリアクセスをコントロールする必要があります。
device_info.pyの実行例ではLocal Mem TypeがGLOBALになっていました。そのようにローカルメモリがグローバルメモリでエミュレートされているようなデバイスも存在します。この場合にはローカルメモリを使用しても高速化は期待できないでしょう。
グローバルメモリへの書き込みを減らす¶
以上のように、OpenCLプログラム、特にGPUを扱う場合はメモリアクセスを最適化することが重要です。先の行列積計算のプログラムを少し変更してみましょう。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import mem_flags
import numpy
import time
size = 1024
a = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
b = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
dest = numpy.empty_like(a)
context = pyopencl.create_some_context(interactive=False)
queue = pyopencl.CommandQueue(context)
a_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=a)
b_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=b)
dest_buf = pyopencl.Buffer(context, mem_flags.WRITE_ONLY, dest.nbytes)
program = pyopencl.Program(context, '''
__kernel void matrix_mul(
__global const int* a,
__global const int* b,
__global int* dest,
const int n
)
{
const int i = get_global_id(0);
const int j = get_global_id(1);
int tmp = 0;
for(int k = 0; k < n; k++){
tmp += a[j * n + k] * b[k * n + i];
}
dest[j * n + i] = tmp;
}
''').build()
n = numpy.int32(size) # カーネル関数にスカラー値を渡すにはnumpyの型を使う
start = time.time()
e = program.matrix_mul(queue, a.shape, None, a_buf, b_buf, dest_buf, n)
e.wait()
stop = time.time()
pyopencl.enqueue_copy(queue, dest, dest_buf)
print numpy.all(numpy.dot(a, b) == dest)
print stop - start
プライベートメモリを使ってグローバルメモリへの書き込みを1回だけに減らしました。テストサーバで実行すると20パーセントの高速化になっていることが確かめられます。このように、OpenCLプログラムではささいな変更でパフォーマンスに大きく影響を与えることがあります。
ローカルメモリを使う¶
上のプログラムではグローバルメモリへの書き込みは1回に減らせたものの、読み込みは依然として2n回行われています。行列積の計算ではグローバルメモリの1つの要素に何度もアクセスされています。ローカルメモリを使ってグローバルメモリからの読み込み回数を減らしましょう。
行列積の計算でローカルメモリを使うために、アルゴリズムを少し変更する必要があります。下図のように、destの部分の値を決定するために、グローバルメモリからローカルメモリに読み込み、ローカルメモリからプライベートメモリへ書き込みという過程を繰り返していきます。

行列積のローカルメモリを使った高速化
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import mem_flags
import numpy
import time
size = 1024
a = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
b = numpy.random.randint(0, 256, (size,size)).astype(numpy.int32)
dest = numpy.empty_like(a)
context = pyopencl.create_some_context(interactive=False)
queue = pyopencl.CommandQueue(context)
a_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=a)
b_buf = pyopencl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=b)
dest_buf = pyopencl.Buffer(context, mem_flags.WRITE_ONLY, dest.nbytes)
program = pyopencl.Program(context, '''
__kernel void matrix_mul(
__global const int* a,
__global const int* b,
__global int* dest,
__local int* local_a,
__local int* local_b,
const int n,
const int m
)
{
const int i = get_global_id(0);
const int j = get_global_id(1);
const int local_i = get_local_id(0);
const int local_j = get_local_id(1);
int tmp = 0;
int local_a_base = get_group_id(1) * m * n;
int local_b_base = get_group_id(0) * m;
int local_index = local_j * m + local_i;
int global_index = local_j * n + local_i;
for(int l = 0; l < n / m; l++){
local_a[local_index] = a[global_index + local_a_base];
local_b[local_index] = b[global_index + local_b_base];
barrier(CLK_LOCAL_MEM_FENCE);
for(int k = 0; k < m; k++){
tmp += local_a[local_j * m + k] * local_b[k * m + local_i];
}
barrier(CLK_LOCAL_MEM_FENCE);
local_a_base += m;
local_b_base += m * n;
}
dest[j * n + i] = tmp;
}
''').build()
n = numpy.int32(size)
local_size = 32
m = numpy.int32(local_size)
local_a = pyopencl.LocalMemory(4 * local_size * local_size)
local_b = pyopencl.LocalMemory(4 * local_size * local_size)
start = time.time()
e = program.matrix_mul(queue, a.shape, (local_size,local_size),
a_buf, b_buf, dest_buf, local_a, local_b, n, m)
e.wait()
stop = time.time()
pyopencl.enqueue_copy(queue, dest, dest_buf)
print numpy.all(numpy.dot(a, b) == dest)
print stop - start
課題3¶
行列とベクトルの積を計算するPyOpenCLプログラムを書いてみましょう。
課題4¶
課題3で作成したプログラムを、メモリアクセスを考慮して高速化してみましょう。
PyOpenCLの便利機能¶
PyOpenCLにはOpenCLをより便利に使うためのショートカットが用意されています。
Array¶
デバイスメモリ上のデータをnumpyのndarrayのように簡単に演算することができます。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import clrandom
from pyopencl import clmath
import numpy
context = pyopencl.create_some_context(interactive=False)
queue = pyopencl.CommandQueue(context)
# numpyのarrayをpyopenclのarrayに変換
a_host = numpy.random.rand(5000).astype(numpy.float32)
a = pyopencl.array.to_device(queue, a_host)
# ゼロクリアされたarrayの生成
b = pyopencl.array.zeros(queue, (5000,), numpy.float32)
# 値がランダムなarrayの生成
c = clrandom.rand(queue, (5000,), numpy.float32)
# 演算
a += 2
a /= 3
a += c
print a.get()
# 数学関数
print clmath.sin(c).get()
# リダクション
print pyopencl.array.sum(b)
テンプレートカーネル¶
配列の値の総和を求めたり、最小値、最大値を求める処理はリダクションと言って、OpenCLで性能を出そうと思うとデバイスの深い知識が必要となり、コードも複雑になります。PyOpenCLではリダクションのためのカーネル関数を抽象化して、必要な処理だけを記述してやるだけで簡単に高速に動作するカーネル関数が作れるようになっています。
スキャンと呼ばれる処理も独特の並列処理が行われるので自前でカーネル関数を作成するのは大変です。リダクションと同様にスキャンの抽象化カーネルも提供されています。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import clrandom
from pyopencl.elementwise import ElementwiseKernel
from pyopencl.reduction import ReductionKernel
from pyopencl.scan import ExclusiveScanKernel
from pyopencl.scan import InclusiveScanKernel
import numpy
context = pyopencl.create_some_context(interactive=False)
queue = pyopencl.CommandQueue(context)
a = clrandom.rand(queue, (5000,), numpy.float32)
b = clrandom.rand(queue, (5000,), numpy.float32)
c = pyopencl.array.empty_like(a)
kernel1 = ElementwiseKernel(context,
'float* x, float* y, float* z',
'z[i] = x[i] * x[i] + y[i] * y[i]')
kernel1(a, b, c)
print c.get()
kernel2 = ReductionKernel(context,
numpy.float32,
neutral='0.0f',
reduce_expr='max(a, b)',
map_expr='i % 2 == 0 ? x[i] : 0.0f',
arguments='__global float *x')
print kernel2(a)
d = pyopencl.array.arange(queue, 1, 11, 1, dtype=numpy.int32)
kernel3 = ExclusiveScanKernel(context, numpy.int32, 'a + b', '0')
kernel3(d)
print d.get()
e = pyopencl.array.arange(queue, 1, 11, 1, dtype=numpy.int32)
kernel4 = InclusiveScanKernel(context, numpy.int32, 'a + b')
kernel4(e)
print e.get()
リダクションカーネルのサンプルとしてモンテカルロ法による超球の体積計算を掲載します。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import clrandom
from pyopencl.reduction import ReductionKernel
import numpy
def create_kernel(context, n):
sum_square_expr = '+'.join('x{0}[i] * x{0}[i]'.format(i) for i in range(n))
arguments = ', '.join('__global float* x{0}'.format(i) for i in range(n))
kernel = ReductionKernel(
context,
numpy.int32,
neutral='0',
reduce_expr='a + b',
map_expr='({0} <= 1.f) ? 1 : 0'.format(sum_square_expr),
arguments=arguments)
return kernel
context = pyopencl.create_some_context(interactive=False)
queue = pyopencl.CommandQueue(context)
N = 1000000
D = 4
points = [clrandom.rand(queue, N, numpy.float32) for _ in range(D)]
kernel = create_kernel(context, D)
result = kernel(*points).get()
print float(result) / N * 2 ** D
課題5¶
PyOpenCLでのアプリケーション開発¶
PyOpenCLはPythonに提供されてる様々なライブラリと連携して高度なアプリケーションを簡単に作ることができます。
ここで取り扱うPIL及びPyOpenGLもpipで簡単にインストールすることができます。
pip install PIL
pip install pyopengl
PIL¶
PILはPythonで画像を扱うためのライブラリです。
PyOpenCLとPILで市松模様の画像を作ってみます。
# -*- coding: utf-8 -*-
import pyopencl
from pyopencl import mem_flags
import numpy
from PIL import Image
context = pyopencl.create_some_context()
queue = pyopencl.CommandQueue(context)
program = pyopencl.Program(context, '''
__kernel void check(__global uchar* out, int size)
{
const int i = get_global_id(0);
const int j = get_global_id(1);
const int base = (j * get_global_size(1) + i) * 3;
if((i / size + j / size) % 2 == 0){
out[base] = 0;
out[base + 1] = 0;
out[base + 2] = 255;
}else{
out[base] = 255;
out[base + 1] = 255;
out[base + 2] = 255;
}
}
''').build()
height = 512
width = 512
out = numpy.empty((height, width, 3), numpy.uint8)
out_buf = pyopencl.Buffer(context, mem_flags.WRITE_ONLY, out.nbytes)
program.check(queue, (height, width), None, out_buf, numpy.int32(32))
pyopencl.enqueue_copy(queue, out, out_buf)
image = Image.fromarray(out)
image.save('check.png')

実行結果
PyOpenGL¶
OpenCLはOpenGLとも密接に関連していて、OpenGLのメモリオブジェクトをカーネル関数で操作することができます。
PyOpenCLでGL統合の機能を使うには、ビルド時にオプションで有効化する必要があります。